大模型在法律服务方面仍有很大提升空间!
“法律问答”专项测评
引言:中国法研一直致力于推动大模型在法律服务方面的应用。近期,中国法研测评中心针对行业内的部分大模型进行了专项测评,形成初步结果,供大家交流和参考。
测评背景
近期,中国司法大数据研究院有限公司信息化测评中心(简称“中国法研测评中心”)收到了大量法律从业者的咨询,他们不仅关注法律大模型在实际应用中的能力表现,还寻求关于法律大模型的建议和推荐。为了回应广大用户的需求,也应中国法律大模型联盟的要求,中国法研测评中心特组建专家团队,针对法律大模型在“法律问答”专项领域上的能力展开了测评工作。
本次测评采用的是中国法研自主研发的测试集,通过API接口和网页界面两种方式进行。测评结果仅基于中国法研的测试集,并不代表所有实际应用场景下的表现。
测试数据集
基于测试数据集选题、文本长度与难易度、语言表达与风格三个维度,构建了内容全面、体系完整的测试数据集,此次针对法律问答的专项测评精选了500个样本作为测试数据集。
1、 测试数据集选题
基于法律从业者实务问题进行总结,形成了相关测试集。测试数据涵盖了民事、刑事、行政、执行、国家赔偿五个领域,占比分别为30%、30%、20%、10%、10%,覆盖了各领域常见及不常见的案件主题。
●测试集样例如下:

数据来源:中国法研信息化测评中心“Super Legal Bench”提供的测试集。
2、文本长度与难易度
根据文本长度分类,包含关键词、句子、段落等不同长度的内容。长度呈现长、适中、短三个不同的维度。难易程度呈现简单、适中、难三个不同的梯度,在测试样本中数量平均分配。
●测试集样例如下:

3、语言表达与风格
结合法律问答面向的不同群体,测试数据包括2种语言风格,每种语言风格各占比50%。
▲输入形式为口语化描述时,语言应用更加生活化,主要服务于不具有法律专业知识的普通用户,应用于日常法律问题咨询等场景。
▲输入形式为法言法语时,语句措辞严谨,多运用法律术语,主要服务于法官、检察官、律师、公司法务人员,应用于法律问题研究、案例阅读等场景。
●测试集样例如下:

评估指标
中国法研参考了《法律大模型评估指标和测评方法(征求意见稿)》及相关标准,此次针对法律问答专项测评的指标包括衡量输出信息综合效能的正确性、完整度、相关度、有效性,共4项指标。
●正确性

●完整度

●相关度

●有效性

测评方法
此次针对法律问答的专项测评,采用自动化测试和人工核查相结合的方式,通过正确性、完整度、相关度和有效性等指标对大模型的法律问答能力进行测评。具体计算公式为:
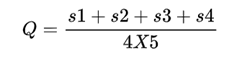
其中:s1、s2、s3、s4分别为正确性、完整度、相关度和有效性的5分制分数。
基于实际测试结果,精选如下示例:
▲示例1:行政协议案件中,能否提出规范性文件附带审查?
(说明:该问题是行政领域问题,语言表达风格为法言法语,文本长度为短,难易程度为简单)

▲示例2:如何理解《劳动合同法》有关“同一用人单位与同一劳动者只能约定一次试用期”的规定?
(说明:该问题是民事领域问题,语言风格为法言法语,文本长度适中,难易程度为难)

▲示例3:不够刑事处罚,存在治安处罚,可以开无犯罪证明吗?
(说明:该问题是行政领域问题,语言风格为法言法语,文本较短,难易程度为简单)

测评结果
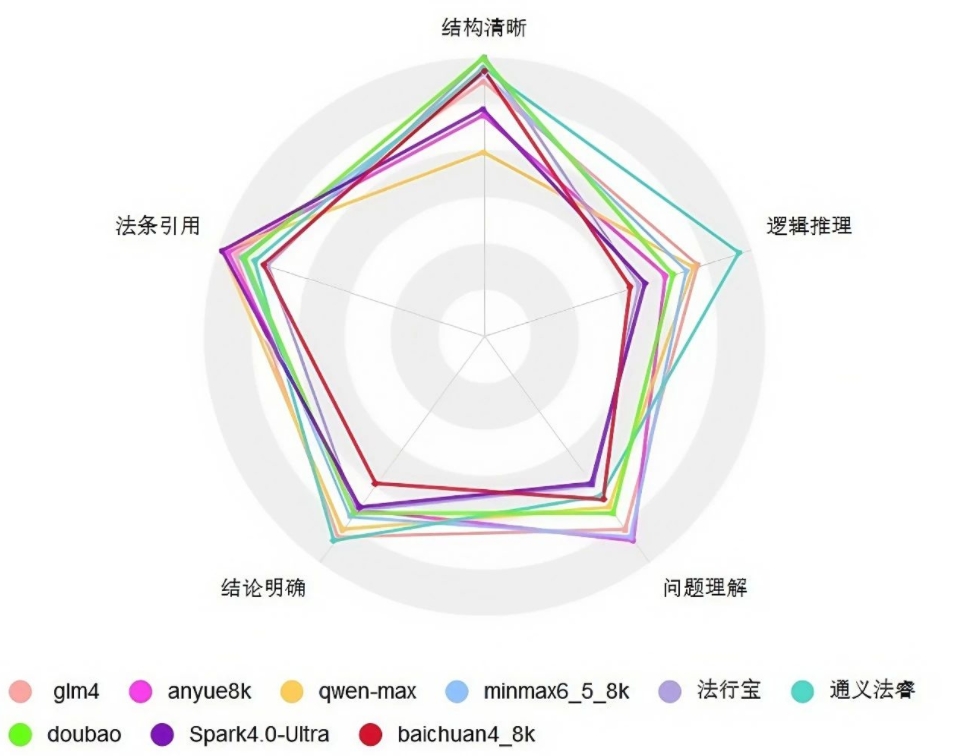
中国法研基于自有的测试集,采用自动化测试和人工核查相结合的方式,通过正确性、完整度、相关度和有效性4个评价维度,对大模型在结构清晰、法条引用、问题理解、逻辑推理和结论明确5大实务维度上的表现进行评估。测评团队对精选后的9个大模型进行了2月余的测试,发现在引用法条方面均表现良好,在逻辑推理和结构化输出能力上存在较大差异,在处理复杂法律问题时,多数模型的解释和推理能力仍有很大的提升空间。9个模型的各项能力评估结果如下:
中国法研测评中心始终致力于大模型测评业务,专注于为大模型的能力提供科学、客观的评估。我们将持续跟进和测评模型的最新版本,密切关注前沿技术动态,确保测评体系能够与时俱进。近期,我们也正在对DeepSeek在法律问答、法考客观题、文书生成和文书解析等方面的能力进行测评。针对上述测评结果,如有问题或意见建议,可电话或邮箱交流,期待与大家共同探索大模型在法律领域的应用潜力。
